Exercise 1 In the file kern/pmap.c, you must implement code for the following functions (probably in the order given).
boot_alloc()
mem_init() (only up to the call to check_page_free_list(1 ))
page_init()
page_alloc()
page_free()
check_page_free_list() and check_page_alloc() test your physical page allocator. You should boot JOS and see whether check_page_alloc() reports success. Fix your code so that it passes. You may find it helpful to add your own assert()s to verify that your assumptions are correct.
总的来说,就是需要实现
boot_alloc()
mem_init()
page_init()
page_alloc()
page_free()
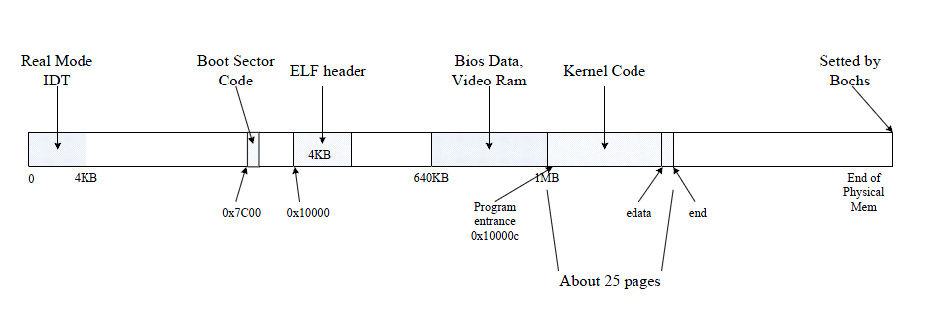
bootloader读入内核代码之后的分布 内存分布
这里主要是引用一下这个图:
可以发现,在刚读取完成内核代码到内存之后。形成的结构如上图所示。
开启分页 分页的机制在《x86汇编语言-从实模式到保护模式》里面介绍得比较清楚。这里就不多说,只引用一张图 :
UVPT UVPT: 需要看 https://pdos.csail.mit.edu/6.828/2014/lec/l-josmem.html
Case 1 如果一个虚拟地址等于0x3BD << 22 | 0x3BD << 12 | 0。kern_pgdir的时候,这个虚拟地址MCU处理之后就是kern_pgdir。
所以 *(0x3BD << 22 | 0x3BD << 12 | 0) == kern_pgdir。
int *p = 0x3BD << 22 | 0x3BD << 12 | 0 ;
for (int i = 0 ; i < 1024 ; i++) {
p[i];
}
所以0x3BD << 22 | 0x3BD << 12 | 0~4096byte地址,就是映射到了char kern_pgdir[4096]
Case 2 那么假设虚拟地址是0x3BD << 22 | 0~1024 | 0这个时候情况又是如何?比如用户程序访问0x3BD << 22这个地址。
1. CR3 = kern_pgdir
2. 高10位值为0x3BD, 页目录项为kern_pgdir[0x3BD]
kern_pgdir[PDX(UVPT)] = PADDR(kern_pgdir) | PTE_U | PTE_P;
不用说,又回到了kern_pgdir
3. 中间10位为0,那么页表为kern_pgdir[0x3BD]指向的物理地址的第0项。
由于kern_pgdir[0x3BD]指向的是kern_pgdir,所以这里页表为kern_pgdir[0]。
kern_pgdir[0]用户程序是可以访问的。在Case 1里面已经验证过了。
4. 虚拟地址就是kern_pgdir[0]指向的物理地址的第0项。不过这个物理地址,用户程序不一定可以访问。
所以总结一下就是0x3BD << 22 | 0 ~ 1024 | xxxx。这个时候,前面20位的地址一解释。指向的地址就是一个kern_pgdir[i]。如果再加上offset = xxxx。实际上这个地址,虚拟地址不一定可以访问。
总结 0x3BD << 22 | 0x3BD << 12 | 0~4096byte地址,就是映射到了char kern_pgdir[4096]
int *p = 0x3BD << 22 | 0x3BD << 12 | 0 ;
for (int i = 0 ; i < 1024 ; i++) {
p[i];
}
UVPT ~ UVPT + 4MB这个虚拟地址应该会有至少一个页目录项。一个页目录项刚好点4MB。结合Case 2。可以发现,
int *p = 0x3BD << 22 | 0x3BD << 12 | 0 ;
for (i = 0 ; i < 1024 ; i++) {
if (*(p+i) & 0x01 ) {
} else {
}
}
boot_alloc 这个函数首先来,end变量是定义在kernel.ld文件里面的。指向了内核地址的尾巴。
注意 这里要到的地址是虚拟地址。不是物理地址。
static void *
boot_alloc (uint32_t n)
{
static char *nextfree;
char *result;
if (!nextfree) {
extern char end[];
nextfree = ROUNDUP((char *) end, PGSIZE);
}
if (0 == n) {
return nextfree;
}
n = ROUNDUP(n, PGSIZE);
result = nextfree;
nextfree += n;
return result;
}
mem_init 这个函数里面分为页管理链表分配空间。
n = sizeof (struct PageInfo) * npages;
pages = (struct PageInfo*)boot_alloc(n);
memset (pagees, 0 , n);
注意看注释,要求全部初始化为0的。
page_init 这里要做的事情很简单,就是把空闲的内存通过双向链表串起来。
void
page_init (void )
{
size_t i;
assert(!page_free_list);
for (i = 1 ; i < npages_basemem; i++) {
pages[i].pp_ref = 0 ;
pages[i].pp_link = page_free_list;
page_free_list = &pages[i];
}
for (i = PADDR(boot_alloc(0 ))/PGSIZE; i < npages; i++) {
pages[i].pp_ref = 0 ;
pages[i].pp_link = page_free_list;
page_free_list = &pages[i];
}
}
page_alloc page_alloc的功能就是从链表中分配一页。这里需要完全照着注释来实现。比如pp_link要设置为空。pp_ref不要去修改。
struct PageInfo *
page_alloc (int alloc_flags)
{
struct PageInfo *ret = page_free_list;
if (!page_free_list) {
return NULL ;
}
page_free_list = ret->pp_link;
ret->pp_link = NULL ;
if (alloc_flags & ALLOC_ZERO) {
memset (page2kva(ret), 0 , PGSIZE);
}
return ret;
}
page_free 这里会把一个pp_ref为0的页表放回到链表中。
void
page_free (struct PageInfo *pp)
{
assert(!pp->pp_ref);
assert(!pp->pp_link);
pp->pp_link = page_free_list;
page_free_list = pp;
}
Excersize 3 xp/Nx paddr -- 查看paddr物理地址处开始的,N个字的16进制的表示结果。
info registers -- 展示所有内部寄存器的状态。
info mem -- 展示所有已经被页表映射的虚拟地址空间,以及它们的访问优先级。
info pg -- 展示当前页表的结构。
Excersize 4 pgdir_walk pgdir_walk只是在给定的页表中查一下虚拟地址的页目录项 。并不需要页目录项与虚拟地址绑定。如果存在页目录项,那么只需要直接返回相应的页目录项。if/else的时候要考虑各种情况。
pte_t *
pgdir_walk(pde_t *pgdir, const void *va, int create)
{
assert(pgdir);
pde_t *pde = &pgdir[PDX(va)];
if (!(*pde & PTE_P)) {
if (!create) return NULL ;
struct PageInfo *page = page_alloc(ALLOC_ZERO);
if (!page) return NULL ;
page->pp_ref++;
assert(page->pp_ref == 1 );
assert(page->pp_link == NULL );
*pde = page2pa(page) | PTE_P | PTE_U | PTE_W;
}
return (pte_t *)(KADDR(PTE_ADDR(*pde))) + PTX(va);
}
boot_map_region 把一个虚拟内存映射一个物理内存。
static void
boot_map_region (pde_t *pgdir, uintptr_t va, size_t size, physaddr_t pa, int perm)
{
for (uint32_t i = 0 ; i < size; i += PGSIZE) {
pte_t *pte = pgdir_walk(pgdir, (const void *)va, true );
*pte = pa | perm | PTE_P;
va += PGSIZE;
pa += PGSIZE;
}
}
注意这里的设置。
page_insert 写这个函数的时候,要特别仔细地把注释读一下。boot_map_region在映射的时候。kern_pgdir里面),这是因为boot_map_region这个函数操作的都是已经在kernel里面申请好的内存。并且页表的管理是从boot_alloc(0)之后才开始管理的。所以内核里面的页在添加到的kernel_pgdir的时候并不会用PageInfo来进行管理。
int
page_insert (pde_t *pgdir, struct PageInfo *pp, void *va, int perm)
{
pte_t *pte = pgdir_walk(pgdir, va, true );
if (!pte)
return -E_NO_MEM;
pp->pp_ref++;
if (*pte & PTE_P)
page_remove(pgdir, va);
*pte = page2pa(pp) | perm | PTE_P;
tlb_invalidate(pgdir, va);
return 0 ;
}
page_lookup 这个函数的功能就是给定一个虚拟地址。然后根据这个虚拟地址来找到相应的物理地址。
struct PageInfo *
page_lookup (pde_t *pgdir, void *va, pte_t **pte_store)
{
pte_t *pte = pgdir_walk(pgdir, va, false );
if (!pte || !(*pte & PTE_P)) return NULL ;
if (pte_store) *pte_store = pte;
return pa2page(PTE_ADDR(*pte));
}
page_remove page_remove这个函数的功能主要是取消虚拟地址与物理地址的关联。
void
page_remove (pde_t *pgdir, void *va)
{
pte_t *pte = NULL ;
struct PageInfo *pp = page_lookup(pgdir, va, &pte);
if (!pp) return ;
*pte = 0 ;
page_decref(pp);
tlb_invalidate(pgdir, va);
}
Excersize 5 mem_init()
这里主要是要把内核里面一些区域设置到页目录中去。
boot_map_region(kern_pgdir, UPAGES, PTSIZE, PADDR(pages), PTE_U);
boot_map_region(kern_pgdir, KSTACKTOP-KSTKSIZE, KSTKSIZE, PADDR(bootstack), PTE_W);
boot_map_region(kern_pgdir, KERNBASE, 0x10000000 , 0 , PTE_W);
接下来还有一系列小问题。比如
kern_pgdir里面的内容是什么? 这个问题其实只需要看一下mem_init里面的boot_map_region就可以了。
What entries (rows) in the page directory have been filled in at this point? What addresses do they map and where do they point? In other words, fill out this table as much as possible:
Entry Base Virtual Address Points to (logically):
1023 ? Page table for top 4MB of phys memory
1022 ? ?
. ? ?
. ? ?
. ? ?
2 0x00800000 ?
1 0x00400000 ?
0 0x00000000 [see next question]
内存保护 We have placed the kernel and user environment in the same address space. Why will user programs not be able to read or write the kernel’s memory? What specific mechanisms protect the kernel memory?
这个问题是因为页表里面有各种保护机制。
最大能支持的内存是多少? * ULIM, MMIOBASE --> +------------------------------+ 0xef800000
* | Cur. Page Table (User R-) | R-/R- PTSIZE
* UVPT ----> +------------------------------+ 0xef400000
* | RO PAGES | R-/R- PTSIZE
* UPAGES ----> +------------------------------+ 0xef000000
这里UPAGES对应的就是pages这个链表。程序空间在利用虚拟地址访问pages的时候。一旦大于4MB,比如越界到了UVPT这个空间。由于这部分虚拟地址是放到了kern_pgdir里面。所以这个时候超出的部分就不能访问了。也就意味着:物理空间上,pages占用多大空间都没有问题。但是虚拟地址空间在访问UPAGES的时候就是不能访问全。因此,能支持的内存大小就变成了2GB。
How much space overhead is there for managing memory, if we actually had the maximum amount of physical memory? How is this overhead broken down? 这里是说现在管理内存的开销是多少?其实直接看虚拟地址就可以明白了。一个页目录表占用4MB。而UPAGES占用了4MB。所以合在一起就是8MB。如果要减小开销。
内存访问的问题 Q1. Revisit the page table setup in kern/entry.S and kern/entrypgdir.c. Immediately after we turn on paging, EIP is still a low number (a little over 1MB). At what point do we transition to running at an EIP above KERNBASE?
Q2. What makes it possible for us to continue executing at a low EIP between when we enable paging and when we begin running at an EIP above KERNBASE? Why is this transition necessary?
Q1. 当还在利用kern/entry.S和kern/entrypgdir.c的时候。一打开分页的时候,EIP还在一个低端的物理地址上。是通过什么方式让EIP跑到KERNBASE之上的内核虚拟地址空间运行的?
mov $relocated, %eax
jmp *%eax
relocated:
# Clear the frame pointer register (EBP)
# so that once we get into debugging C code,
# stack backtraces will be terminated properly.
movl $0x0,%ebp # nuke frame pointer
Q2. 问的是说,实际上当打开分页的时候,EIP还是在低地址运行。然后再通过跳转跑到高端地址。打开分页的时候,EIP指向下一条指令。即`move $relocated, %eax`的内存地址。为什么访问这个内存地址不会失败?
kern/entrypgdir.c 中将 0 ~ 4MB 和 KERNBASE ~ KERNBASE + 4 MB 的虚拟地址都映射到了 0 ~ 4MB 的物理地址上,因此无论 EIP 在高位和低位都能执行。必需这么做是因为如果只映射高位地址,那么在开启分页机制的下一条语句就会crash。
`